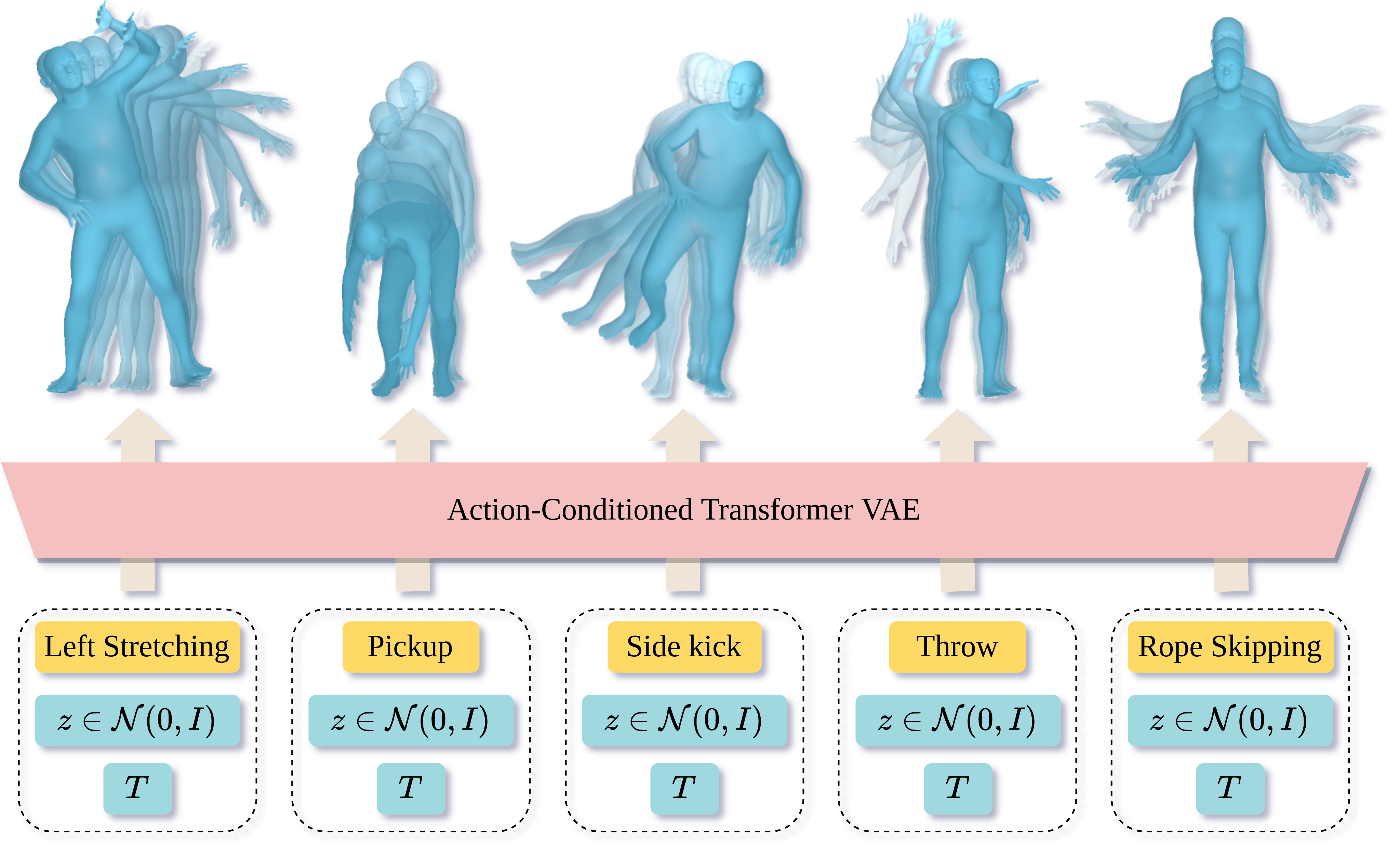
We tackle the problem of action-conditioned generation of realistic and diverse human motion sequences. In contrast to methods that complete, or extend, motion sequences, this task does not require an initial pose or sequence. Here we learn an action-aware latent representation for human motions by training a generative variational autoencoder (VAE). By sampling from this latent space and querying a certain duration through a series of positional encodings, we synthesize variable-length motion sequences conditioned on a categorical action. Specifically, we design a Transformer-based architecture, ACTOR, for encoding and decoding a sequence of parametric SMPL human body models estimated from action recognition datasets. We evaluate our approach on the NTU RGB+D, HumanAct12 and UESTC datasets and show improvements over the state of the art. Furthermore, we present two use cases: improving action recognition through adding our synthesized data to training, and motion denoising. Code and models are available on our project page.
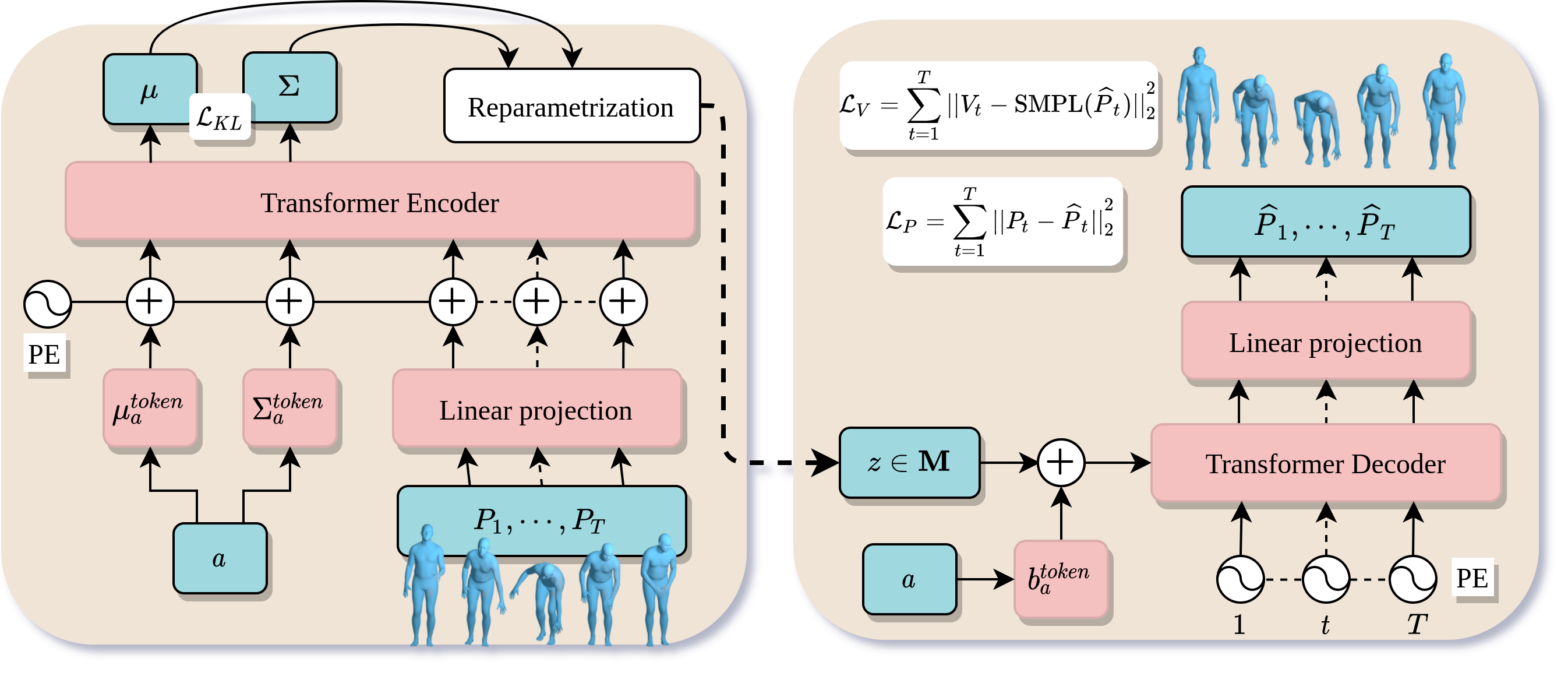
Encoder: Given a sequence of body poses
and an action label
, the encoder outputs
distribution parameters on which we define a KL loss
.
We use extra learnable tokens per action (
and
)
as a way to
obtain
and
from the Transformer encoder.
We sample from
and
the latent representation
(the encoded input).
Decoder: It takes the latent vector
, an action label
, and a duration
as input.
The action determines the learnable
additive token,
and the duration determines the number of positional encodings (PE) to input to the decoder.
The decoder outputs the whole sequence
against which
the reconstruction loss
is computed.
In addition, we compute vertices with a differentiable SMPL layer
to define a vertex loss
.
Generator: The decoder alone is simply the generator, where the encoded input is replaced by a vector randomly sampled from a Gaussian distribution.
Please refer to the video for more examples and see other experiments (different durations, interpolation in latent space, loss ablation).
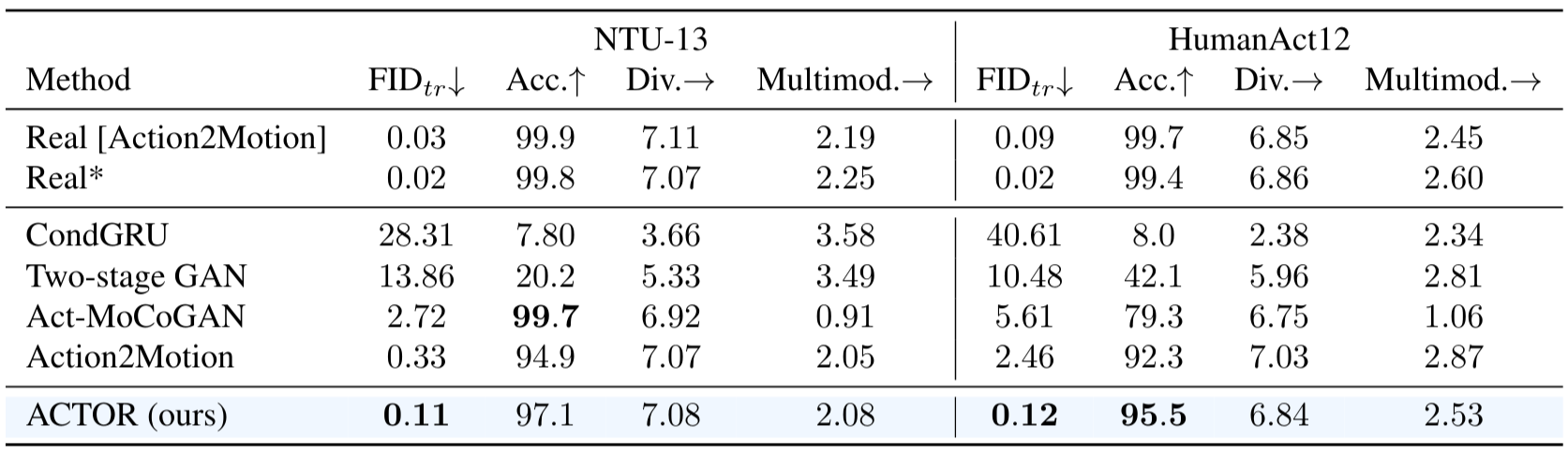
Please refer to the paper to get more details.
If you find this project useful for your research, please cite
@inproceedings{petrovich21actor,
title = {Action-Conditioned 3{D} Human Motion Synthesis with Transformer {VAE}},
author = {Petrovich, Mathis and Black, Michael J. and Varol, G{\"u}l},
booktitle = {International Conference on Computer Vision ({ICCV})},
year = {2021}
}
This work was granted access to the HPC resources of IDRIS under the allocation 2021-101535 made by GENCI. The authors would like to thank Mathieu Aubry and David Picard for helpful feedback, Chuan Guo and Shihao Zou for their help with Action2Motion details.
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright.